
Written by Florin — full-stack & AI engineer.
Latest articles

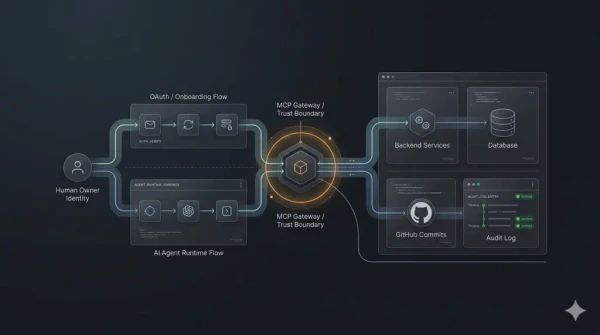
MCP Is Not Just an API Wrapper: Designing Trust Boundaries for AI Agents
The Mistake I Keep Seeing With MCP Model Context Protocol is often introduced as a cleaner way to connect AI agents to tools. That is true…
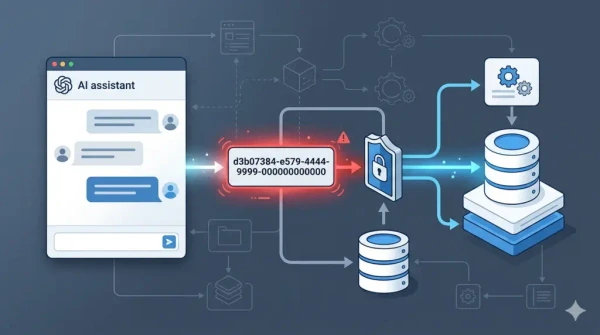
When AI Agents Hallucinate IDs
A Production Bug That Changed One of My Rules for Tool Calls A customer asked a booking assistant a normal question: Do you have…

Review Debt: The Cognitive Cost of AI-Assisted Coding
The hidden tax nobody is measuring, and four practices for managing it. A few months back, I shipped four features in two days. By Friday of…
AI Engineering · 3 posts
MCP Is Not Just an API Wrapper: Designing Trust Boundaries for AI Agents
The Mistake I Keep Seeing With MCP Model Context Protocol is often introduced as a cleaner way to connect AI agents to tools. That is true…
When AI Agents Hallucinate IDs
A Production Bug That Changed One of My Rules for Tool Calls A customer asked a booking assistant a normal question: Do you have…
Review Debt: The Cognitive Cost of AI-Assisted Coding
The hidden tax nobody is measuring, and four practices for managing it. A few months back, I shipped four features in two days. By Friday of…
Algorithms · 3 posts


Valid Parentheses
Problem Given a string containing just the characters '(', ')', '{', '}', '[', and ']', determine if the input string is valid. Description…


Climbing Stairs
Problem You are climbing a staircase with n steps. At each step, you can climb either 1 or 2 steps. Determine the number of distinct ways to…

Anagram
Problem Given two strings, a and b, write a function to determine if a is an anagram of b Description This is a classic algorithm problem…
LangChain · 6 posts

Schema-Driven Validation for Stable LLM Evaluations
My earliest eval runs looked fine until they didn't: a single malformed row could flip a whole report. That was on me. The fix was simple…

Why Averages Lie: Using Tags to Expose Hidden LLM Regressions
Averages hide real problems. I learned that the hard way: a bundle recommender looked stable overall, but a single region-specific slice was…

Tracing LLM Pipelines: From Bug Report to Root Cause
The fastest way I've found to debug an LLM app isn't logs. It's a trace. A good trace shows exactly where the chain broke, which inputs…
Node.js · 1 posts


System Design · 2 posts

Scaling to 1 Million Requests Per Second: A Practical Guide
You're in a system design interview. The interviewer asks: "How would you handle 1 million requests per second?" Your mind races. Where do…

Reliable Order: Moving from `Hope-Based` Retries to Async Workflows
Every production system has a moment where the simple approach stops being enough. Real systems don't become unreliable overnight — they…